An autonomous research lab for agentic systems.
Any agent. Any experiment. Deep evals.Learn about and improve any agentic system — with evidence to back every claim.
Just want to follow along? Get updates →
Insights from each run sharpen the next — runs in, research out.
If you can run it, Bunsen can eval it.
Bunsen is a universal eval lab you can point at any task: benchmarks, zero-to-one product builds, coding agents, your own Claude Code customizations, and more. In fact, we've ported Terminal Bench 1.0 to Bunsen — and, as an example, we had Claude Code use the bn CLI to create BattlesnakeBench, where models compete to create the best Battlesnake bot.
A whole benchmark, code-scored.
The full canonical Terminal Bench 1.0 port runs in Bunsen — 66 real-world tasks across nine categories. We also ported Terminal Bench's deterministic scorers over as Bunsen scorers, so evaluating tasks costs nothing. Browse the port →
Seriously — eval anything.
Claude Code used the bn CLI to create BattlesnakeBench — here are two models' bots, each scored by win-rate* against a hidden, held-out ladder of reference snakes:
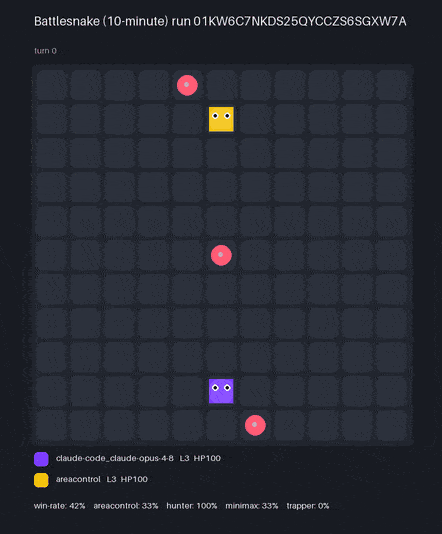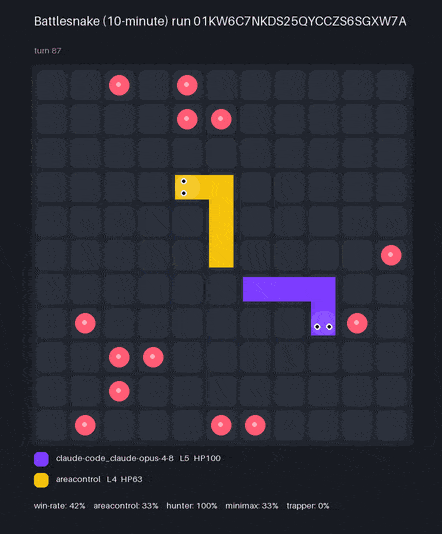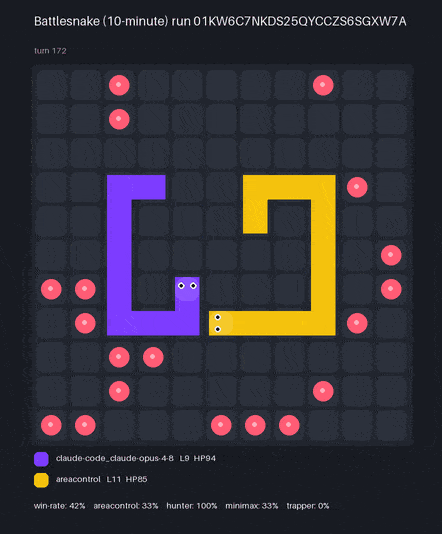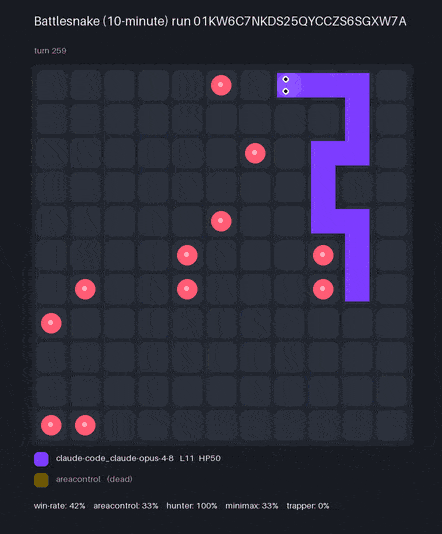

* Win-rate over 36 games per model (9 seeds × 4 hidden reference bots). The official engine spawns snakes nondeterministically, so a single run varies by ~±3% (1 SD) — the model ranking holds across repeated scorings. Each replay is one game, not the full ladder.
Maximum power, minimum setup.
Install the CLI, scaffold a project with the frontier coding agents already wired up, then write your first experiment — a folder with a task and a rubric. Every run is fully instrumented — traces, artifacts, diffs, and cost — captured automatically, with zero changes to the agent.
Node 22+ and Docker — run bn doctor to verify your environment. claude-code, codex-cli, and gemini-cli ship ready; bringing your own agent is ~10 lines of YAML — start from a bundled one, or run bn skills install and let your agent write it. See the docs.
An experiment is just a folder.
An experiment.yaml, optional verifier scripts your rubric calls, and a workspace seeded into the container. That's the whole thing.
$schema: …/experiment.v1.json version: v1 name: gcal-clone task: prompt: Build a calendar app in /workspace — month / week / day views. workspace: sources: - path: ./workspace evaluation: criteria: - id: builds type: script run: bash /bunsen/verifiers/build.sh scores: [0, 1] - id: views type: browser-agent instructions: Make sure the month / week / day views work.
Even this starter rubric pairs a deterministic check with a browser-agent. For the full range of agentic scorers, see Deep by default ↓.
Deep by default.
Agentic scorers — agents that investigate and evaluate the artifacts produced by a task — are the heart of Bunsen's eval system. Bunsen grades the agent by giving it a real task and digging into what it produced. Scorers run a spectrum: from deterministic checks to AI agents that explore the workspace, drive a browser, and read the run's own traces, each citing its evidence. Because agentic scorers are expensive, Bunsen lets you gate them behind $0script scorers — paying for deep judgment only where it's warranted.
The gcal-clone rubric
A gate, an agent that audits the code for security holes, two browser-agents — one drags an event, one checks the layout across breakpoints — and a math roll-up. One folder; a whole eval stack.
evaluation: criteria: - id: builds # gate — skip the rest unless it compiles type: script run: bash /bunsen/verifiers/build.sh scores: [0, 1] # allowed values — omit for continuous 0–1 gate: { ifBelow: 1 } - id: security # an agent audits the source and cites file:line type: agent instructions: Audit for injection / XSS — unsanitized titles, an unsafe ICS export. - id: drag-and-drop # a browser-agent drives real Chromium type: browser-agent instructions: Drag to create an event, move it to another day — does it stick? - id: responsive # graded 0 / .25 / .5 / .75 / 1, not pass/fail type: browser-agent scores: [0, 0.25, 0.5, 0.75, 1] instructions: Does the layout hold at 375 / 768 / 1280 px? - id: overall # pure-math roll-up, no LLM type: aggregate needs: all aggregate: { function: weighted_average }
Run the tests, grep the output — anything you can do in code; the exit code is the score. Deterministic, and the gate that short-circuits everything below it.
One LLM call over the diff — or the logs, or the agent's own traces. A score with explicit reasoning.
A tool-using loop: run_command, read_file, read the agent's trace turns. It explores, runs things, and cites what it found.
Drives a real Chromium via Playwright — clicks, screenshots, and verifies a built UI actually works.
Pure math over the other scores — all-pass gates, weighted means, min/max. No LLM call.
Cheap checks gate the expensive ones — a deterministic script short-circuits a browser-agent, so you only spend judgment where it matters. Skipped is recorded as skipped, never a fake zero.
Toward an autonomous research lab.
Bunsen runs on its own agents: inside every run, they drive the agent under test, read its traces, and score the result. The bigger goal is an autonomous lab that runs the whole research loop — proposing the questions, running the matrix, and writing up the findings. We're not there yet, but the last two steps already work: running the matrix produced the sweep below, and turning those runs into a cited write-up is what Bunsen did next.
| Agent (model) | Pass rate | Cost / pass |
|---|---|---|
| codex-cli (gpt-5.5) | 92% · 11/12 | $0.31 |
| claude-code (Opus 4.7) | 92% · 11/12 | $1.66 |
| claude-sdk-agent (Sonnet 4.5) | 60% | $0.30 |
| gemini-cli (2.5 Pro) | 58% | $0.47 |
Given nothing but 46 run IDs from a finished sweep — no hint of the tasks, the agents, or the scoring — Bunsen reconstructed the entire study and wrote it up, citing specific runs and traces that held up to an adversarial check at zero discrepancies. Runs in, research out.
Upcoming — a productized meta-analysis command (bn report) and a fully self-directed loop where Bunsen proposes its own research questions.
From agent to evidence.
Bring any agent
Claude Code, Codex, Gemini, and the Claude SDK ship ready — or add your own (Pi, OpenCode, your in-house agent) in ~10 lines of YAML pointing at a command. No SDK, no wrapper class.
Run it in a container
Any task you can run in Docker. Drop the files the agent works on in workspace/, write the prompt and a rubric, and Bunsen instruments the run for you — every API call, diff, log, and cost, captured with zero changes to the agent.
Score it with AI
Scorers from deterministic checks up to AI agents that run your tests, drive a real browser, and read the run's own traces. The whole ladder, out of the box.
Bring any agent. Bring any task. Bunsen brings the insights and the evidence.
The CLI is source-available today — curl -fsSL https://bunsen.dev/install.sh | sh. Join the list for release notes and new findings as they ship.
Release notes + new findings. No spam, unsubscribe anytime.